- 데이터베이스 : 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음
SQL(관계형 데이터베이스)과 NoSQL(비 관계형 데이터베이스)로 나뉨
- 관계형 데이터베이스(RDBMS) : 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스를 가리키며 SQL이라는 언어를 써서 조작함.
- NoSQL 데이터베이스 : SQL을 사용하지 않는 데이터베이스를 말하며 유연한 스키마, 확장성이 특징
SQL(관계형 데이터베이스)
SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있음
관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다.
- 데이터는 관계를 통해 여러 테이블에 분산된다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.
또한, 데이터의 중복을 피하기 위해 '관계'를 이용한다.

하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
대표적으로 MySQL (구조 : 레코드 - 테이블 - 데이터베이스)
NoSQL (비관계형 DB)
말그대로 관계형 DB의 반대다.
스키마도 없고, 관계도 없다!
NoSQL에서는 레코드를 문서(documents)라고 부른다.
여기서 SQL과 핵심적인 차이가 있는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다. 하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
문서(documents)는 Json과 비슷한 형태로 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다.
따라서 위 사진에 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다.
따라서 여러 테이블에 조인할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다. (NoSQL에는 조인이라는 개념이 존재하지 않음)
그러면 조인하고 싶을 때 NoSQL은 어떻게 할까?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.
하지만 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 조인을 잘 사용하지 않고 자주 변경되지 않는 데이터일 때 NoSQL을 쓰면 상당히 효율적이다.
대표적으로 MongoDB (구조 : 도큐먼트 - 컬렉션 - 데이터베이스)
NoSQL데이터베이스 - MongoDB
MongoDB는 JSON을 통해 데이터에 접근할 수 있고, Binary JSON 형태(BSON)로 데이터가 저장되며 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스입니다. 확장성이 뛰어나며 빅데이터를 저장할 때 성능이 좋고 고가용성과 샤딩, 레플리카셋을 지원합니다. 또한, 스키마를 정해 놓지 않고 데이터를 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석하거나 로깅 등을 구현할 때 강점을 보입니다.
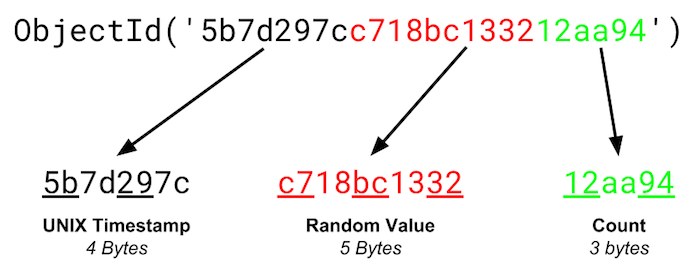
또한, MongoDB는 도큐먼트를 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 유니크한 값인 ObjectID가 생성됩니다. 이는 기본키로 유닉스 시간 기반의 타임스탬프(4바이트), 랜덤 값(5바이트), 카운터(3바이트)로 이루어져 있습니다.
1. key와 value 형태의 도큐먼트
MongoDB 내의 도큐먼트는 key-value 형태로 이루어지며 _id라는 고유한 아이디를 가집니다. 그리고 DB에 저장될 때 key의 길이도 내용으로 들어갑니다. 또한 MongoDB는 JSON 형태로 쿼리를 만들고 JSON을 매개변수로 받아 BSON 형태로 DB에 삽입, 추출하는 것이 가능합니다. 그래서 type 변환이 일어나지 않으며, 이를 통해 JSON 데이터를 주고받을 때 성능 면에서 더 좋은 선택이 됩니다.
2. 스키마 없이 삽입 가능, but?
MongoDB는 RDBMS와 달리 스키마 없이 데이터 모델을 구현하지 않은 채 유동적으로 데이터를 삽입할 수 있습니다. 스키마란 데이터베이스를 구성하는 속성, 관계 등 데이터 값이 갖는 type을 명시해놓은 것을 말합니다. 이를 통해 다양한 서비스로부터 데이터를 유동적으로 쌓을 수 있는 장점을 갖게 됩니다.
하지만 스키마를 미리 설정해놓고 DB에 저장하는 RDBMS는 칼럼의 길이가 DB에 저장되지 않지만 MongoDB는 다릅니다. 예를 들어 RDBMS인 경우 어떤 한 스키마가 int, char[14]인 경우 그 안에 들어가는 데이터인 18바이트만 저장되지만, MongoDB는 한 도큐먼트로 칼럼이름도 바이트에 추가됩니다. key-value 형태로 들어가기 때문이죠. 예를 들어 comments : string이란 type으로 정해놓고 DB에 저장한다면 comments라는 길이의 byte, 즉 8byte가 각각 더 들어가게 됩니다.
(Value값뿐만 아니라 Key 값도 들어가서 저장공간이 더 필요)
3. 데이터의 조합함수 지원
MongoDB는 min, max, aggregate, mapReduce 등 강력한 함수로 데이터를 추출하고 조합해서 압축된 결괏값을 만들어낼 수 있습니다.
4. 이중화 지원과 샤딩
서버는 멈추면 안 되기 때문에 운영서버의 경우 서버 이중화를 합니다. 이때 MongoDB 는 ReplicaSet을 이용해 이중화를 가능하게 합니다. 또한 데이터의 양이 많은 경우 샤딩을 통해 collection을 분할해 관리할 수 있습니다.
5. JSON 형태의 Data
MongoDB는 BSON 형태로 저장되며 JSON 형태의 값으로 추출해낼 수 있습니다. 또한 JSON Object를 매개변수로 받아 쉽게 저장할 수 있습니다.
6. 2차원 좌표 인덱싱
MongoDB는 geoSpartial이란 인덱스를 써서 2차원 좌표를 인덱싱할 수 있습니다.
7. collection join
MongoDB는 $lookup을 통한 collection join이 가능합니다.but,
9. B-tree를 적용한 인덱싱
무언가를 찾고자 할 때 사용되는 것이 인덱싱입니다. 인덱싱이 있어야 빠르게 데이터를 찾을 수 있습니다. 인덱스의 기본 정렬은 항상 오름차순으로 구현되지만 데이터를 추출할 때 또는 인덱스를 초기에 설정할 때는 오름차순이나 내림차순으로 변경할 수 있습니다. 인덱스는 B-tree로 구성되어 있고, 앞서 설명한 2차원 좌표 인덱싱의 경우 R-tree로 구성되어 있습니다.
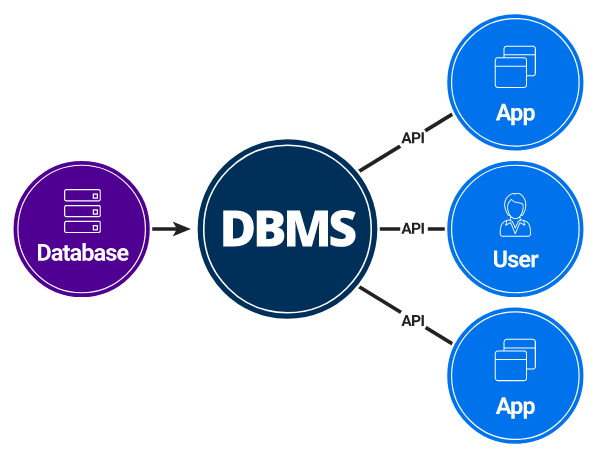
- 데이터베이스 관리 시스템(DBMS) : 데이터를 한곳에 모은 저장소를 만들고 그 저장소에 여러 사용자가 접근하여 데이터를 저장 및 관리 등의 기능을 수행하며 공유할 수 있는 환경을 제공하는 응용 소프트웨어 프로그램
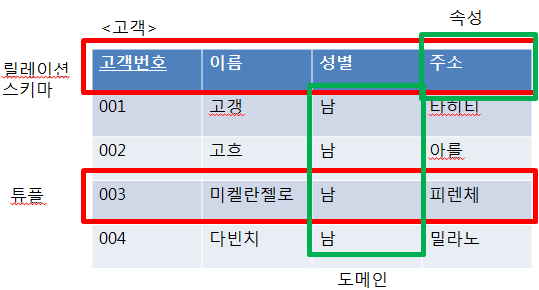
- 엔터티 : 사람, 장소, 물건, 사건, 개념 등 여러 개의 속성을 지닌 명사
* 약한 엔터티 : 혼자서 존재하지 못함(종속적) ex) 방
* 강한 엔터티 : 혼자서 존재 가능 ex) 건물
- 릴레이션 : 데이터베이스에서 정보를 구분하여 저장하는 기본 단위, 릴레이션은 관계형
데이터베이스에서는 ‘테이블’이라고 하며,NoSQL 데이터베이스에서는 ‘컬렉션’이라고 함.
- 속성 : 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보 ex) 사람이라면 성별
- 도메인 : 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합 ex) 성별의 {남, 녀}
- 필드 : 회원이란 엔터티는 member라는 테이블로 속성인 이름, 아이디 등을 가지고 있다고 한다면 name, ID, addreess 등의 필드를 가진다.
레코드를 튜플이라고 부름 (레코드 == 튜플)
- 테이블 CRUD [생성(Create), 조회(Read), 업데이트(Update), 제거(Delete)]
테이블과 컬렉션의 차이
MySQL의 구조는 레코드-테이블-데이터베이스로 이루어져 있음. MongoDB 데이터베이스의 구조는
도큐먼트-컬렉션-데이터베이스로 이루어져 있음.

필드 타입 : 필드는 타입을 갖음, 예를 들어 이름은 문자열이고 전화번호는 숫자이다. 이러한 타입들은 DBMS마다 다르다. MySql 기준으로 설명한다면 여러 가지 타입이 있고 대표적인 타입인 숫자, 날짜, 문자 타입이 있다.
숫자 - INT
4바이트, -21억 ~ 21억
날짜 타입
- DATE : 날짜만, 시간x, 3바이트
- DATETIME : 날짜 + 시간 / 8바이트
- TIMESTAMP : 날짜 + 시간 / 4바이트 / 1970-01-01 00:00:01에서 카운트값.
문자 타입 - CHAR, VARCHAR
- CHAR는 테이블을 생성할 때 선언한 길이로 고정되며 길이는 0에서 255 사이의 값, 레코드를
저장할 때 무조건 선언한 길이 값으로 ‘고정’해서 저장됨
- VARCHAR는 가변 길이 문자열, 길이는 0에서 65,535 사이의 값.입력된 데이터에 따라
용량을 가변시켜 저장
CHAR과 VARCHAR의 차이
CHAR은 이래나 저래나 4바이트씩 저장(고정적), VARCHAR는 유동적으로 저장되는 것을 볼 수 있음

ENUM과 SET
ENUM과 SET모두 문자열을 열거한 타입
ENUM은 단일 선택만 가능, 잘못된 값을 삽입하면 빈 문자열이 대신 삽입됨
SET은 여러개의 데이터를 선택가능, 비트 단위 연산 수행 가능, 최대 64개의 요소를 집어 넣을 수 있음
장점 : 둘 다 공간적 이점을 가짐
단점 : 애플리케이션 수정에 따라 데이터베이스의 ENUM이나 SET에서 정의한 목록을 수정해야함
관계
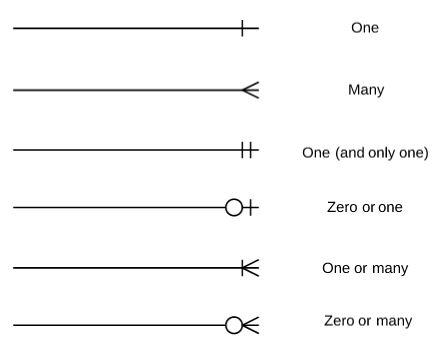
데이터베이스에 테이블은 하나만 있는것이 아니다. 여러개의 테이블이 있고 이러한 테이블은 서로의 관계가 정의되어 있다. 이러한 관계를 화살표로 나타낸다.
키
테이블 간의 관계를 조금 더 명확하게 하고, 테이블 자체의 인덱스를 위해 설정된 장치
- 기본키(Primary Key) : 유일성과 최소성을 만족함.(자연키나 인조키 중에서 하나 설정)
- 자연키 : 중복되는 것을 제외하고 자연스럽게 뽑아 결정하는 기본키, 언젠가 변함
ex) 주민등록번호 021121이라면 2102년생이 생길 수 도 있어서 나중에는 변하게 됨
- 인조키 : MySQL의 auto increment 등인조적으로 유일성을 확보하는 키. 기본키는 보통 인조키로 설정.
ex) 인위적으로 만듬, ex 1, 2, 3, 4
- 외래키 : 다른 테이블의 기본키를 그대로 참조하는 값 (개체와의 식별을 위해 사용)
ex) 고객 리스트 테이블이 있고, 상품 테이블이 있다면 상품이 고객리스트의 고객 번호를 참조하는 형태
(같이 수정하는 번거로움 해소)
- 후보키 : 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족하는 키
- 대체키 : 후보키가 두 개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키들
- 슈퍼키 : 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키
ERD(Entity Relation Diagram)
ERD는 데이터베이스를 구축할 때 가장 기초적인 뼈대 역할을 하며, 릴레이션 간의 관계들을 정의한 것, ERD는 시스템의 요구 사항을 기반으로 작성되며 이 ERD를 기반으로 데이터베이스를 구축합니다.
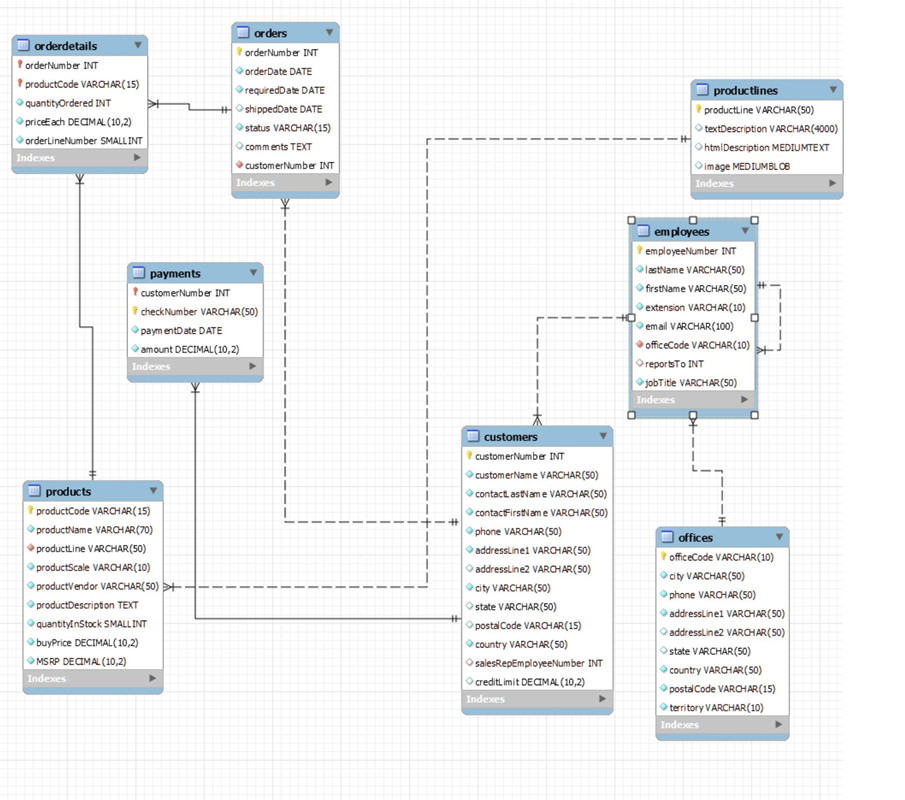
테이블 생성 예시(MySQL)
CREATE TABLE `customers` (
`customerNumber` int(11) NOT NULL,
`customerName` varchar(50) NOT NULL,
`contactLastName` varchar(50) NOT NULL,
`contactFirstName` varchar(50) NOT NULL,
`phone` varchar(50) NOT NULL,
`addressLine1` varchar(50) NOT NULL,
`addressLine2` varchar(50) DEFAULT NULL,
`city` varchar(50) NOT NULL,
`state` varchar(50) DEFAULT NULL,
`postalCode` varchar(15) DEFAULT NULL,
`country` varchar(50) NOT NULL,
`salesRepEmployeeNumber` int(11) DEFAULT NULL,
`creditLimit` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`customerNumber`),
KEY `salesRepEmployeeNumber` (`salesRepEmployeeNumber`),
CONSTRAINT `customers_ibfk_1` FOREIGN KEY (`salesRepEmployeeNumber`)
REFERENCES `employees` (`employeeNumber`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;decimal(10, 2) = 소수부분을 포함한 실수의 총자리수 10자리, 2개의 소수를 가지는 실수.
KEY : 인덱싱을 할 키를 하나 더 생성, salesRepEmployeeNumber를 외래키로 설정한 것을 주목.
orderdetails
orderdetails : 복합키(compound key) orderNumber + productCode
- 왜? 1주문(ordernumber)안에 있는 상품코드들이 많다고 해보자. 이를 구분하기 위해서는 2개의 키를 결합해서 해야 유일성 + 최소성을 만족한다.

트랜잭션, 커밋, 롤백 그리고 트랜잭션 전파
- 트랜잭션 : 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위(쿼리를 묶는
단위)
- 커밋 : 여러 쿼리가 성공적으로 처리되었다고 확정하는 명령어, 트랜잭션 단위로 수행되며
변경된 내용이 모두 영구적으로 저장.
- 롤백 : 트랜잭션으로 처리한 하나의 묶음 과정을 일어나기 전으로 돌리는 일(취소)
트랜잭션의 특징 ACID
원자성 : “all or nothing”
트랜잭션과 관련된 일이 모두 수행되었거나 되지 않았거나를 보장하는 특징
ex) 1000만원을 가진 홍철이가 0원을 가진 규영이에게 500만원을 이체한다고 해보자. 그렇다면 겨로가는 홍철이는 500만원, 규영이는 500만원을 가질 것이다. 다음과 같은 operation 단위들로 이루어진 과정을 거침
1. 홍철의 잔고를 조회한다.
2. 홍철에게서 500만원을 뺀다.
3. 규영에게 500만원을 넣는다.
여기서 1 ~ 3의 operation 중 데이터베이스 사용자는 이 세가지 과정을 볼 수도 참여할 수도 없다. 다만 이 과정이 끝난 이후의 상황인 홍철 500만원, 규영 500만원인 상황만 보는 것
여기서 이 작업을 취소한다고 했을때 홍철이는 다시 1000만원, 규영이는 0원을 가져야 한다. 일부 operation만 적용된 홍철이는 500만원, 규영이는 0원이 되지 않는 것 의미한다. 그래서 all or nothing인 것
일관성
‘허용된 방식’으로만 데이터를 변경해야 하는 것을 의미함.
ex) 범석이는 0원, 홍철이는 500만원이 있다라고 칩시다. 범석이가 500만원을 홍철이에게 입금할 수 있을까? 불가능하다.
0원을 가진 범석이는 500만원이 나오는 것은 불가능하다.
격리성
트랜잭션 수행 시 서로 끼어들지 못하는 것을 말함.
지속성
성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것을 의미함.
데이터 베이스의 시스템 장애가 발생해도 원래 상태로 복구하는 회복 기능이 있어야 하는 뜻이며, 데이터베이스는 이를 위해 체크섬, 저널링, 롤백 등의 기능을 제공
* 체크섬 : 중복검사의 한 형태로, 오류 정정을 통해 송신된 자료의 무결성을 보호하는 단순한 방법
* 저널링 : 파일 시스템 또는 데이터베이스 시스템에 변경 사항을 반영(commit)하기 전에 로깅하는 것, 트렌젝션 등 변경 사항에 대한 로그를 남기는 것
무결성
무결성이란 데이터의 정확성, 일관성, 유효성을 유지하는 것을 말함.
무결성이 유지 되어야 데이터베이스의 저장된 데이터 값과 그 값에 해당하는 현실 세계의 실제 값이 일치하는지에 대한 신뢰가 생긴다.
개체 무결성, 참조 무결성, 고유 무결성, NULL 무결성이 있다.
개체 무결성
기본키로 선택된 필드는 빈 값 허용 안함
참조 무결성
서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지하여야 함
고유 무결성
특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성 값은 모두 고유한 값을 가짐
NULL 무결성
특정 속성 값에 NULL 이 올 수 없다는 조건이 주어진 경우 그 속성 값은 NULL이 될 수 없다는 제약 조건
격리성과 격리수준에 따른 현상(phantom read와 non repeatable read의 차이 등)
격리 수준은 serializable, repeatable_read, read_committed , read_uncommitted 가 있으며 위로 갈수록 동시성이 강해지지만 격리성은 약해지고, 아래로 갈수록 동시성은 약해지고 격리성은 강해집니다.
repeatable_read는 팬텀 리드, read_committed 는 팬텀 리드, 반복 가능하지 않은 조회가 발생하며, read_uncommitted 는 팬텀 리드, 반복 가능하지 않은 조회, 더티 리드가 발생할 수도 있습니다
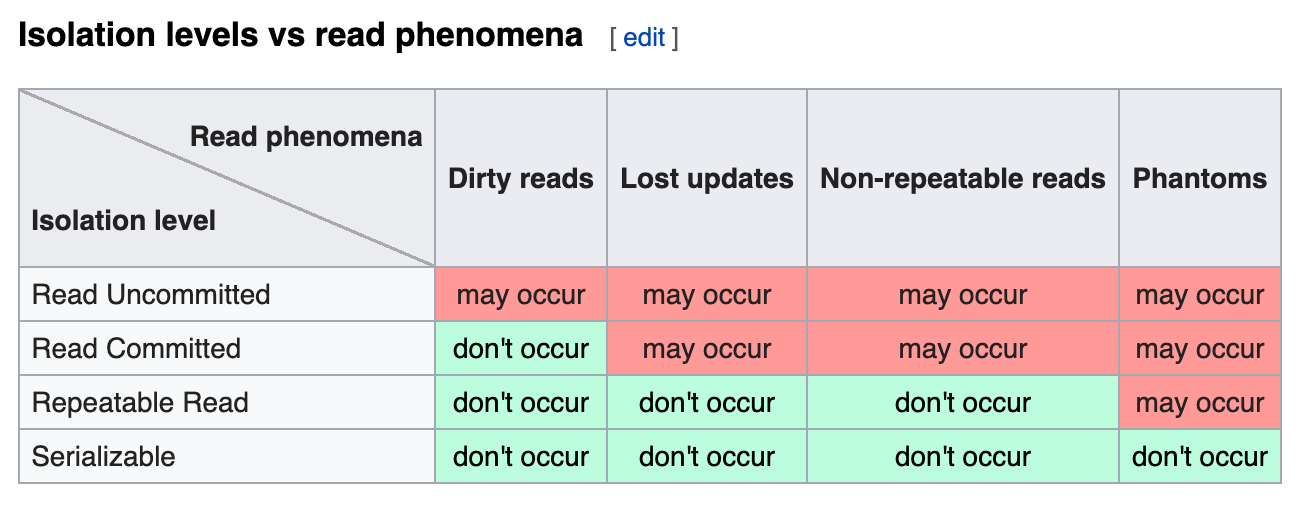
격리 수준에 따라 발생하는 현상
격리 수준에 따라 발생하는 현상은 팬텀 리드, 반복 가능하지 않은 조회, 더티 리드가 있습니다.
- 팬텀 리드 : 한 트랜잭션 내에서 동일한 쿼리를 보냈을 때 해당 조회 결과가 다름
ex) 사용자 A가 회원 테이블에 age가 12이상인 회원들을 조회하는 쿼리를 보내서 이 결과로 3개의 테이블이 조회된다고 해보자. 그 다음 사용자 B가 age 15인 횐원 레코드를 삽입한다. 그러면 그 다음 3개가 아닌 4개의 테이블이 조회되는 것이다.
- 반복 가능하지 않은 조회 : 한 트랜잭션 내의 같은 행에 두 번 이상조회가 발생했는데, 그 값이 다름
ex) 사용자 A가 보석개수 100개라는 값을 가진 데이터였는데, 그 이후 사용자 B가 그 값을 1로 변경해서 커밋했다고 하면 사용자 A는 100이 아닌 1을 읽게 됨
- 더티 리드 : 반복 가능하지 않은 조회와 유사하며 한 트랜잭션이 실행 중일 때다른 트랜잭션에 의해 수정되었지만 아직 ‘커밋되지 않은’ 행의 데이터를 읽을 수 음.
ex) 사용자 A가 보석 개수 100을 1로 변경한 내용이 '커밋되지 않은'상태라도 그 이후 사용자 B가 조회한 결과가 1로 나오는 경우를 말함
격리 수준
- serializable : 트랜잭션을 순차적으로 진행시키는 것 (동시성 저하)
- repeatable _read : 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않음.
- read_committed : 가장 많이 사용되는 격리 수준, read_uncommitted 와는 달리 다른 트랜잭션이 커밋하지 않은 정보는 읽음. 어떤 트랜잭션이 접근한 행을 다른 트랜잭션이
수정할 수 있음.
- read_uncommitted : 가장 낮은 격리 수준. 하나의 트랜잭션이 커밋되기 이전에 다른 트랜잭션에 노출되는 문제가 있지만 가장 빠름.
데이터베이스의 핵심, 스토리지엔진(innoDB, MyISAM, wiredtiger 차이)
innoDB와 myISAM 차이
Innodb : MySQL 8.0 default 엔진, but MyISAM으로 변경 가능
1.InnoDB는 MyISAM 에 비해 데이터베이스 크기가 커짐에 따라 더 큰 가용성을 제공합니다.
2.행, 인덱스 조회 캐싱 : MyISAM은 파일 시스템 블록 캐시에 의존하는 반면 InnoDB는 엔진 자체 내에서 행 캐시와 인덱스 캐시를 결합하여 이 작업을 수행합니다.
3.MyISAM은 테이블 수준의 잠금 제공, InnoDB는 행 수준 잠금을 사용합니다.
4.MyISAM은 항상 테이블에 ROW COUNT를 가지고 있어 조회 쿼리시 빠르다.
5.InnoDB는 트랜잭션 처리, 대용량 데이터를 다루기에 좋고 트랜잭션이 필요없고 조회기능이 많을 때 MyISAM이 좋다.
Wiredtiger 엔진 : MongoDB의 default엔진(3.2 이상부터)
wiredTiger 엔진은 LSMTree(로그 기반 병합트리)를 이용하여 읽기 성능을 포기하고 그만큼 저장 성능을 향상시키고 느린 읽기 성능을 보완하기 위해 블룸 필터를 사용한 엔진입니다. MongoDB는 다음과 같은 특징들이 있는데 아래 특징들이 이 엔진 아래에서 관장됩니다.
1. 체크포인트 : MongoDB는 60초 간격으로 체크포인트를 생성, 또한 MongoDB가 종료되거나 새로운 체크포인트를 작성하는 동안 오류가 발생하더라도 다시 시작하면 MongoDB는 마지막 유효한 체크포인트에서 복구할 수 있습니다. 체크포인트를 기반으로 복구가 가능
2. 저널링 : 로깅라고 부를 수 있는 저널링이 가능. 체크포인트 간의 모든 데이터 수정 사항을 유지합니다. MongoDB가 체크포인트 사이에 종료되면 저널을 사용하여 마지막 체크포인트 이후 수정된 모든 데이터를 재생산 할 수 있음.
3. 압축 : WiredTiger를 통해 MongoDB는 모든 컬렉션 및 인덱스에 대한 압축을 지원합니다.
4. 메모리 : 약 50%의 메모리를 차지 예를 들어 총 4GB의 RAM이 있는 시스템에서 WiredTiger 캐시는 1.5GB의 RAM을 사용합니다( 0.5 * (4 GB - 1 GB) = 1.5 GB). 반대로 총 1.25GB의 RAM이 있는 시스템은 WiredTiger 캐시에 256MB를 할당합니다. 이는 전체 RAM의 절반에서 1기가바이트를 뺀 값( 0.5 * (1.25 GB - 1 GB) = 128 MB < 256 MB)이기 때문입니다.
인덱스의 구조와 효율적인 이유
균형잡힌 B-Tree기반으로 구축되어있어서 탐색에 평균 O(logN) 시간이 걸리며 트리 생성시의 대수확장성이란 특징으로 인해 더 빠른 시간안에 많은 양의 데이터를 빠르게 찾을 수 있기 때문.
* 대수 확장성 : 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미
기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가합니다.
인덱스 최적화 기법
- 1. 인덱스는 비용이다 : 먼저 인덱스는 두 번 탐색하도록 강요합니다. 인덱스 리스트, 그 다음 컬렉션 순으로 탐색하기 때문이며, 관련 읽기 비용이 들게 됩니다.
- 2. 항상 테스팅하라
- 3. 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티(유니크한 값의 정도) 순
clustered index와 non-clustered index와의 차이
clustered index
- 클러스터형 인덱스, 유일성과 최소성을 가지는 기본키 중 하나로 설정. 테이블당 한개, 보통 테이블의 기본키가 클러스터형 인덱스가 됩니다.
- 데이터페이지가 정렬되서 저장되며 인덱스 페이지의 리프노드에 “데이터페이지”가 들어가 있음. 정렬되었기 때문에 탐색에 장점.
- 데이터가 추가될 때마다 다시 모든 테이블을 정렬해야 하기 때문에 삽입, 삭제, 수정이 느림.
- 인덱스의 순서와 데이터의 순서가 일치함.

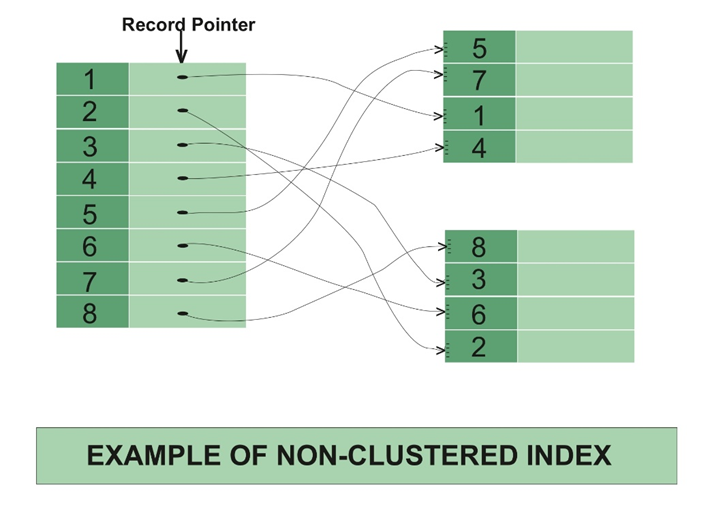
non-clustered index
- 보조인덱스라고 함. 한 개가 아닌 여러개를 만들 수 있음. 클러스터형키가 복합키가 될 수도 있긴하나 보통 복합키를 만든다고 했을 때 (compound key) 보조인덱스로 만듬.
- 클러스터형과는 달리 인덱스 페이지 리프노드에 실제 데이터가 있는 것이 아니라 데이터 페이지에 관한 포인터가 있음.
- 정렬되어있지 않아서 탐색은 느리나. 삽입, 삭제, 수정이 빠름.
- 인덱스의 순서와 데이터의 순서가 일치하지 않음.
클러스터형 인덱스 생성방법
primary key : 클러스터형
alter table add primary key
보조 인덱스를 만드는 방법
create index ..
alter table add index
주의! 무조건 primary key로 설정한다고 해서 클러스터형 인덱스로 설정되는 것이 아님.
SQL Server의 경우 다음과 같은 반례가 있음. 다음 코드 처럼 할 경우 보조 인덱스로 설정됨
* 데이터베이스마다 만드는 방법이 다름.
/* Non-clustered index */
ALTER TABLE MyTable
ADD CONSTRAINT PK_MyTable
PRIMARY KEY NONCLUSTERED(WidgetId);
내부조인, 왼쪽조인, 오른쪽조인, 합집합 조인의 차이
조인(join)이란 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것을 말함.
- 내부 조인(inner join): 왼쪽 테이블과 오른쪽 테이블의 두 행이 모두 일치하는 행이 있는 부분만 표기합니다.
- 왼쪽 조인(left outer join): 왼쪽 테이블의 모든 행이 결과 테이블에 표기됩니다.
- 오른쪽 조인(right outer join): 오른쪽 테이블의 모든 행이 결과 테이블에 표기됩니다.
- 합집합 조인(full outer join): 두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기함.

중첩루프조인, 정렬병합조인, 해시조인의 차이
- 중첩 루프 조인 : 중첩 for 문과 같은 원리로 조건에 맞는 조인
ex) 테이블A, 테이블B를 조인한다고 했을때, 테이블A에서 행을 한번에 하나씩 읽고, 테이블B에서도 행을 하나씩 읽어 조건에 맞는 레코드를 찾아 결과값을 반환한다.
- 정렬 병합 조인 : 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인 <, > 조건에 많이 쓰임.
ex) 테이블A, 테이블B를 조인한다고 했을떄, 각 테이블을 정렬하고 조인작업을 수행한다. 조금 더 빠르게 할 수 있다.
- 해시 조인 : == 조건에만 쓰임. 두 개의 테이블을 조인한다고 했을 때 바이트상 더 작은 테이블을 해시테이블로 만들어서 조인
바이트상 더 작은 테이블을 메모리에 올려놓고 하는 방법
각 레코들에 대해 hash 함수로 고정된 길이로 바꾸고, 찾을때도 hash함수로 고정된 길이 문자열로 바꿔서 찾으므로
O(n)이 걸림
데이터베이스의 데드락과 해결방법
데드락
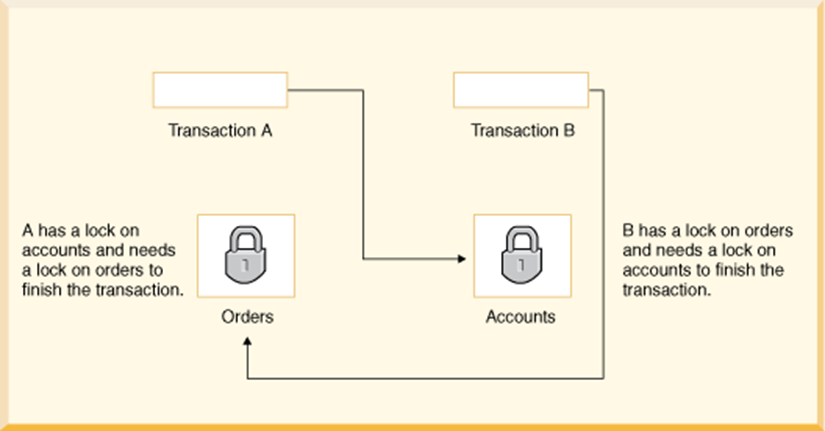
데이터베이스에서 교착 상태는 둘 이상의 트랜잭션이 서로가 잠금을 포기하기를 기다리는 상황입니다.
“accounts테이블”과 “order테이블”이 있다고 했을 때 transaction A는 accounts 테이블의 일부 행에 잠금을 건 상태로 이 트랜잭션을 완료하려면 order 테이블의 일부 행을 업데이트 해야 합니다.
transactionB도 그와 같은 상황이죠. (order잠금, accounts 데이터항목이 필요)
이 때 둘 중 하나를 중단하지 않는 한 모든 활동이 중단되는 상태입니다
교착상태 감지
1. 교착상태 감지 및 timeout
일정시간(timeout)이후 트랜잭션이 실행되지 않았을 경우 롤백
2. 그래프기반으로 사이클 탐색 그래프 내의 사이클이 형성되었다라는 것을 기반으로 교착상태를 감지
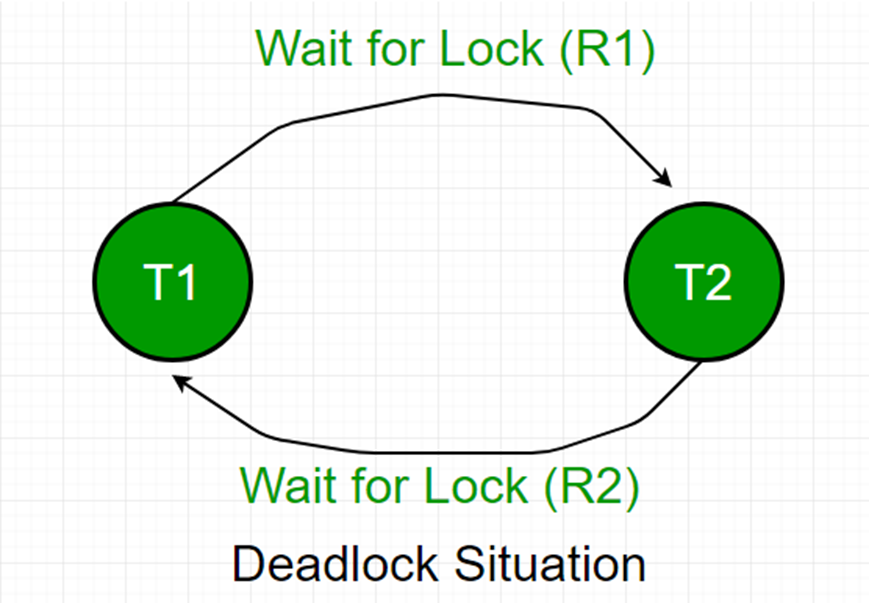
but, 대규모 데이터베이스의 경우 이를 일일히 감지하기에 너무나 코스트가 크기 때문에 교착상태방지를 많이 씁니다
교착상태방지
- 최대한 교착상태가 일어나지 않게 방지
1. 격리수준 변경
교착 상태를 방지하기 위해 격리수준을 행수준 잠금 또는 격리 수준을 조정하는 것. serializable이 아닌 이상 모든 교착상태를 완전히 제거하는 것은 아니다.
2. 서비스의 로직을 교차되지 않게 수정
되는 수준으로 또는 서비스의 논리구조를 바꾸는 것. accounts > order(accounts 다음에 order) 이런식으로 서로 교차되지 않고 일관성있게 바꾸는 방법
3. wait-die(비선점) 또는 wound wait(선점) 방법
타임스탬프를 기반으로 트랜잭션을 대기, 선점, 종료하는 방식
* TIMESTAMP : 타임스탬프 값은 '1970-01-01 00:00:01' UTC부터 시작하는 초수를 나타냄.
- Wait-Die 방식 : 트랜잭션 방지를 위한 비선점기법
“대기하거나 죽거나” 늙은 것이 요구하면 대기하고, 젊은 것이 요구하면 감히? 하면서 젊은 것은 죽는 것.
ex) 트랜잭션 T 5 , T 10 , T 15 에 각각 타임스탬프 5, 10 및 15가 있다고 가정합니다.
T 5 가 T 10 이 보유한 데이터 항목을 요청하면 T 5 는 "대기"합니다.
T 15 가 T 10 이 보유한 데이터 항목을 요청 하면 T 15 는 죽습니다.

[wait die / 수염있는게 조금 더 오래된 트랜잭션입니다.]
- wound – wait : 교착 상태 방지를 위한 선점 기법 입니다 .
“상처를 입거나 대기하거나” 늙은 것이 요구하면 젊은 것은 강제로 일시정지, 데이터는 늙은이의 것. 젊은 것이 요구하면 대기.
ex)
다시, 트랜잭션 T 5 , T 10 , T 15 에 각각 타임스탬프 5, 10 및 15가 있다고 가정합니다.
T 5 가 T 10 이 보유한 데이터 항목을 요청하면 데이터 항목이 T 10 에서 선점되고 T 10 이 일시 중단됩니다. (wound)
T15 가 T10 이 보유한 데이터 항목을 요청하면 T15 는 " 대기 "합니다. (wait)

출처 : 면접을 위한 CS 전공지식 노트
'CS > 데이터베이스' 카테고리의 다른 글
| ORACLE / MySQL / MSSQL 이중화 종류 특징 (0) | 2025.11.21 |
|---|---|
| 데이터베이스 면접 질문 (0) | 2022.09.28 |