필요한 개념
Thread 이론
Thread 전에 Process라는 개념을 알아야한다.
실행파일에 하나의 프로세스가 있을 수도 있지만 여러개의 프로세스가 있을 수도 있다.
* 프로세스가 왜 생겼냐?
예전 도스는 운영체제가 실행할 수 있는 프로그램이 하나밖에 실행 안됨(원래는 운영체제가 실행될때 여러 프로그램이 실행이 되도록 작업이 되었지만, 도스는 그럼)
시간이 지나면서 사람들이 여러개의 프로그램을 동시에 사용하고 싶어하는 니즈 등장
윈도우 프로그램 -> 여러개의 동시에 프로그램이 동작가능하도록 함
그래서 프로세스라는 단위가 필요해짐
작업 관리자 들어가면
ex) 반디캠에도 옆에 내리는 버튼 누르면 하나에 프로그램에 여러개의 프로세스가 있다.
여러개의 프로세스를 나눠서 동시에 실행되는 것처럼 보이게 하는 기법(멀티 테스킹, 멀티 프로세싱, 멀티 프로그래밍 다 동일한 개념)
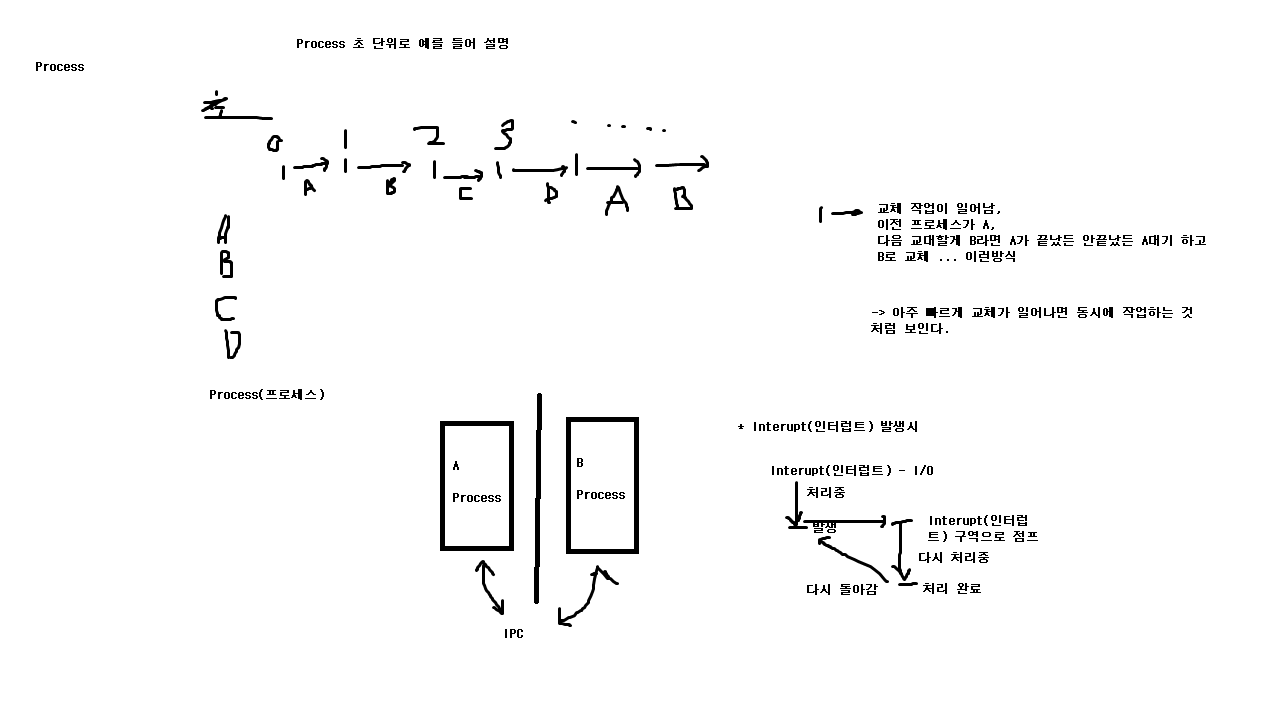
각각의 Process간 메모리 공유 불가(독립적인)
프로세스 A, B는 같은 영역이 아님
*만약에 메모리 공유한다면, A 프로세스가 B 프로세스의 메모리를 가져다가 변경을 할 수 있게 되버린다.(해킹)
-> 방지하기위해 구역을 나누게 되었다.
그런데 A 프로세스와 B 프로세스 간의 통신해야할 일이 생긴다.
메세지를 주고 받아야 한다.
통신하기 위해 프로그래머들이 기능을 만들었다.
IPC(Inter Process Communication) : 프로세스간에 통신을 하기 위한 기법
IPC 기법 2가지
1) MessageMap
2) Pipeline
....
*) 면접 나올 수도 있다.
IPC 기법의 모든 문제는 치명적인 Interupt(인터럽트)가 발생
* Interupt(인터럽트) 발생 조건
Interrupt(인터럽트) 발생 원인
- 프로그램을 실행하는 도중에 예기치 않은 상황이 발생할 경우 현재 실행중인 작업을 즉시 중단하고, 발생된 상황을 우선 처리한 후 실행중이던 작업으로 복귀하여 계속 처리하는 것, 일명 "끼
cpplab.tistory.com
1) I/0(입출력)가 수행되면 발생함(대표적인 발생 조건)
MessageMap은 하드디스크에다가 메세지를 한쪽에 저장했다가 꺼내다 쓰는 방식
(하드 디스크에다가 접근해서 읽는 것은 Interupt(인터럽트) -> 입출력)
- 큰 파일을 읽을 때 프로그램이 정지되어있는거 처럼 보임(응답없음) -> 대표적인 Interupt(인터럽트) 현상
- Sleep() 함수를 써보았을 것이다. 이 함수는 지정한 시간만큼 강제로 Interupt(인터럽트)를 발생시킨다.
Interupt(인터럽트)가 발생이 되면 Interupt(인터럽트)구역으로 점프를 해서 다시 처리를 해서 처리가 완료 되었을때
다시 돌아간다.
함수가 이와 비슷하게 처리된다. -> 그래서 함수를 소프트웨어적 인터럽트라고 한다.
pipeline도 네트워크 처럼 동작한다. 데이터가 랜카드 까지 나갔다가 들어옴. 랜카드 까지 나갔다 들어오는 것이
입출력(I/O)를 발생시킨다. -> Interupt(인터럽트) 발생
I/O든 하드디스크든 LAN카드 든 모두 RAM에서 어디론가 데이터를 주고 받는다면 모두 입출력이라고 생각하라.
(CPU와 주고 받는 것들은 아님)
IPC는 인터럽트를 발생시키기 때문에 느리다.
-> 그래서 사람들이 고민(꼭 프로세스 단위로만 나눠야 하나? 더 작은 단위로 CPU에 할당될 수 있는 단위로 작업을
나누자해서(메모리 공유나 이런것이 문제되지 않겠다.해서 나온게 Thread이다.)
Thread : 프로세스 내에서 CPU에 할당될 수 있는 단위로 분할 한것, 하나의 스레드는 하나의 함수를 물고 실행됨
(프로세스 단위로 나누기 때문에 메모리 공유에 대한 문제가 없다, 결국엔 나눠서 쓰는것이어서 동시에 실행시킨거
처럼 보임) -> 멀티 프로세스와 동일하게 작동
(CPU에 할당될 수 있는 최소한의 크기)
쓰레드는 cpu에 할당될 수 있는 최소한의 크기이다.(운영체제마다 크기(바이트 수)가 다르다.)
시스템적인 이유, 프로그래밍 적인 이유로 쓰레드가 할당되서 처리되는 시간보다
A -> B로 쓰레드가 교체되는 시간이 더 걸린다.(Context Switching)
*반드시 나오는 문제
Context Switching : 스레드가 처리되는 시간보다 교체되는 시간이 더 걸리는 비효율적이 상황
(-> 효율이 가장 떨어짐) 어떻게 발생하냐 보단 어떤 의미를 가지는지가 중요
기본적으로 쓰레드는 1개가 동작하고 있다.
우리가 whie문으로 렌더링코드를 작성하고 있다.
if 메세지가 들어온다면 메세지 처리하고 아니라면 렌더링하는 유효시간에 렌더링하고 업데이트를 수행하고 있다.
(window class에 있다. 우리가 만든)
MSG msg = { 0 };
while (true)
{
// 메세지가 들어왔다면 메세지 처리
if (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
if (msg.message == WM_QUIT)
break;
TranslateMessage(&msg);
DispatchMessage(&msg);
}
// 아니라면 렌더링
else
{
MainRender();
}
}
mainExecute->Destroy();
이 부분이다.
이미 기존에 쓰레드가 하나 돌고 있다 가정(이 루프 안에서 쓰레드를 만들게 되면, 멀티쓰레드가 된다.)
(메인렌더링도 하나의 쓰레드가 돌고 있다고 생각하면 된다. 우리가 스레드를 하나 더 할당하면 멀티쓰레드가 된다.)
Thread -> 프로그래머는 함수 단위라고 생각하면 된다.(함수 단위로 실행)
A 쓰레드는 A 함수를 물고 실행하고, B 쓰레드도 B 함수를 물고 실행한다....
함수들이 빠르게 오고 가게 실행됨
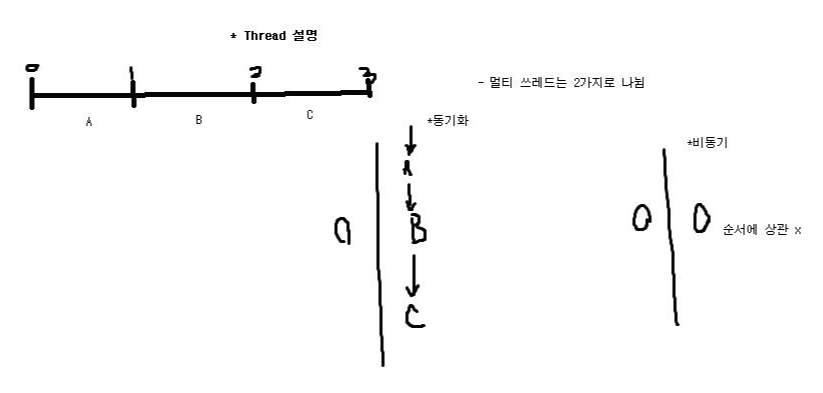
멀티 쓰레드는 2가지로 나뉨
1) 동기 방식
A -> B -> C(A, B, C는 쓰레드)
동기화 -> 멀티 쓰레드 내에서 순서대로 실행되도록 처리
1개의 쓰레드가 동작하고 있고, 다른 1개 쓰레드도 실행된다면
옆에 쓰레드가 순서대로 간다면 동기화 쓰레드
2) 비동기 방식
순서에 상관 없이 호출됨
1개의 쓰레드가 동작하고 있고, 다른 한개의 쓰레드가 실행된다면(순서에 상관없이 실행된다면)
비동기 이다.
동기보다는 비동기를 많이 사용
동기화는 11에선 중요해짐, 11에서는 멀티쓰레드가 기본적으로 사용될 수 있도록 멀티쓰레드가 프로그래밍화 되어있다.(다루진 않음)
Multi Thread(멀티 쓰레드) : 하나의 쓰레드가 동작하고 있는데 다른 하나가 또 동작하고 있다면(쓰레드는 함수 단위)
순서대로 동작한다면 동기화
그렇지 않다면 비동기화
* 쓰레드 사용하는 방법 2가지
- WinAPI에 있는거 사용하는 방법
- STL에 있는거 사용하는 방법
STL에 있는 것이 좀 더 다루기 간단해서 이것으로 사용해볼 것임
* 우리는 스레드를 왜 배우나?
DirectCompute를 하기 위해 Thread를 배움
스레드는 함수단위여서 함수가 필요
스레드를 사용하려면(stl로) #include <thread>하면 된다.
Mutex 이론
Mutex : race condition 상태에서 변수에 접근 제한하는

예를 들면) 고속도로에서 화장실이 급해서 차를 세우고 임시화장실에 갔다. 그러나 많은 사람이 서서 대기하고 있고 이미 화장실 안에 사람이 있다.
화장실에서 사람이 볼일을 보고 나간다면 밖에 사람들이 줄 서 있지 않고 막무가내로 있다고 생각한다면 누가 들어갈지 모른다.(쓰레드가 줄을 서있는게 아니다. 누가 들어가게 될지 모른다.)
-> 경쟁상태(Race Condition) : 임계 영역에서 스레드가 처리되고 나온 상황에 다른 스레드들이 들어가려고 서로 경쟁하는 상태
화장실의 역할이 임계영역이다.
임계 영역(Critical Section) : 어떤 변수를 하나의 스레드만 접근해서 쓸 수 있도록 묶어놓는 구역
int a = 0이 있다면
A 스레드가 a에 접근해서 값을 쓴다고 가정하고,
B 스레드가 a값을 가져다 쓴다면
A 스레드가 a를 10으로 바꿔놓고
B 스레드가 a를 가져다 쓴다면 문제가 없다.
그러나 A가 값을 바꿔놓기 전에 B가 a를 가져다 쓴다면...
-> B가 a가 0인 상태에서 가져다 쓰고 그 후 A가 a에다가 값을 쓸 것이다.
경쟁상태에서는 A가 먼저 접근할지 B가 먼저 접근할지 알 수가 없다. 둘다 접근해서 쓸일이 없겠지만 만약 그렇다면 문제가 생긴다.
순서라든가, 한 명이 접근해서 이미 작업을 하고 있었다면 작업을 불가 상태로 만들기 위해 변수 a 구역을 임계영역을 만든다.
화장실에 들어갔다면 제일 먼저하는 일은 문부터 잠그는 것이다.
할일을 마쳤다면 문을 열고 나온다.
A스레드가 만약에 a 변수 구역에 임계영역에 접근 했다면 lock을 걸어서 임계영역으로 만들어준다.(A를 제외한 나머지 스레드는 접근 불가 상태가 된다.)
A가 자기 작업을 모두 완료했다면 unlock을 해주고 다시 이 구역에서 나오게 된다.
나머지 경쟁상태에 있던 스레드가 임계영역에 다시 들어간다.
* 2가지 용어 알아 둘것
임계 영역을 하나만 두면 뮤텍스
여러개의 스레드를 접근해서 사용할 수 있도록 카운팅을 이용하는 기법이 세마포어(관찰 알고리즘에 있다.) -> 찾아보기(관찰 알고리즘)
화장실에 들어갔는데, 영원히 안나온다. -> 데드락(교착상태)에 빠짐
한명이 lock을 해버려서 들어갈 수 가 없다. 대기 상태에 빠짐
중요(면접에서 잘 나옴)
* 데드락(교착상태)에 빠지는 4가지 상황
* 데드락 발생을 방지하기 위한 기법 4가지
정리한 사이트 참고
https://cpplab.tistory.com/55
DeadLock(교착상태)
교착 상태의 조건 1971년에 E. G. 코프만 교수는 교착상태가 일어나려면 다음과 같은 네 가지 필요 조건을 충족시켜야 함을 보였다. 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대
cpplab.tistory.com
ThreadDemo.h
#pragma once
#include "Systems/IExecute.h"
class ThreadDemo : public IExecute
{
public:
virtual void Initialize() override;
virtual void Ready() override {};
virtual void Destroy() override {};
virtual void Update() override;
virtual void PreRender() override {};
virtual void Render() override;
virtual void PostRender() override {};
virtual void ResizeScreen() override {};
private:
void Loop();
// stl의 <functional> 사용 테스트
// 함수포인터를 다루기 위해
// 게임에서 많이 사용됨 ex) 문을 열었다. 이벤트 발생
void Function();
void MultiThread();
void MultiThread1();
void MultiThread2();
void Join();
void Mutex();
void MutexUpdate();
void RaceCondition(int& counter);
void Execute();
void ExecuteTimer();
void ExecutePerformance();
private:
// #include <mutex>
mutex m;
// 임계 영역을 만들 변수
float progress = 0.0f;
Timer timer;
Timer timer2;
};
ThreadDemo.Cpp
#include "stdafx.h"
#include "ThreadDemo.h"
void ThreadDemo::Initialize()
{
//Loop();
// 함수포인터
// 1 : 함수, 2 : 어느 객체에 있는지
//function<void()> f = bind(&ThreadDemo::Function, this);
//f();
//MultiThread();
//Join();
//Mutex();
//Execute();
//ExecuteTimer();
ExecutePerformance();
}
void ThreadDemo::Update()
{
//MutexUpdate();
}
void ThreadDemo::Render()
{
}
void ThreadDemo::Loop()
{
for (int i = 0; i < 100; i++)
printf("1 : %d\n", i);
printf("반복문 1 종료\n");
for (int i = 0; i < 100; i++)
printf("2 : %d\n", i);
printf("반복문 2 종료\n");
}
void ThreadDemo::Function()
{
printf("함수 포인터 호출\n");
}
void ThreadDemo::MultiThread()
{
// ()안에 함수포인터가 들어간다. -> #include <functional> 해줘야함
// 2 스레드가 동시에 작동되서 멀티스레드 상황이다.
thread t(bind(&ThreadDemo::MultiThread1, this));
thread t2(bind(&ThreadDemo::MultiThread2, this));
// Debug에러가 나오는데 일단 무시하자
// 해보면 1번 실행되었다가, 2번 실행되었다가 왔다갔다함
// 이거는 실행할때마다 항상 다름
// 얼마만큼 할당되서 얼마만큼 처리될지는 운영체제마다 다름(환경에 따라 다름)
// 예측 불가(순서)
// 그래서 순서 제어가 필요하다면 -> 동기화 스레드를 사용
// Debug 에러가 발생되는 이유 :
// Thread가 종료되어야 되면 반드시 join이 콜 되어야함
// join이 호출되지 않으면 해당 스레드의 처리가 끝나지 않으므로 에러가 발생
// 또한 해당 스레드의 join은 해당 스레드의 실행이 완전히 완료되어야 수행된다.
// t2.join을 만나면 t2가 종료될때 까지 대기를 함(다음 밑에 코드 안넘어감)
t2.join();
printf("t2.join\n");
// t가 종료되지 않으면 그 뒤 코드로 안넘어감
t.join();
printf("t.join\n");
// 그래서 여기 보면은 printf("t2.join\n");가 printf("t.join\n");보다 항상 먼저 나온다.
// 그 뒤 코드로 안넘어가고 완료될때 까지 대기를 해서
}
void ThreadDemo::MultiThread1()
{
for (int i = 0; i < 100; i++)
printf("1 : %d\n", i);
printf("반복문 1 종료\n");
}
void ThreadDemo::MultiThread2()
{
for (int i = 0; i < 100; i++)
printf("2 : %d\n", i);
printf("반복문 2 종료\n");
}
void ThreadDemo::Join()
{
// 람다식을 사용
// 람다식 : 익명 메서드를 사용하기 위해 주로 사용
// 문법을 익혀두면 유용하게 사용가능하다.
// =을 쓰면 맴버변수를 이안에 쓰는 것이되고, &을 쓰면
// 위에 전역이거나 맴버에 있는것을 받는다. *도 가능
//thread t([=]()
//{
//});
// 파라미터 받는 것도 가능
//thread t([](int a)
//{
//});
// join을 쓸때는 순서에 주의 해야 한다.
// ex) t2가 무한루프를 돌고 있다면, 뒤에 코드가 실행되지 않는다.
thread t([]()
{
for (int i = 0; i < 100; i++)
printf("1 : %d\n", i);
printf("반복문 1 종료\n");
});
thread t2([]()
{
int a = 0;
while (true)
{
a++;
printf("A : %d\n", a);
// 1/10초 만큼
Sleep(100);
if (a > 30)
break;
}
});
printf("멀티 쓰레드 시작\n");
t2.join();
printf("t2 join\n");
t.join();
printf("t join\n");
// 결과 : 반복문 1 종료가 떴음에도 불구하고 t join이 되지 않았다.
// t2 join이 되어서야 t join이 되었다.
// -> join 순서에 유의해서 작성해야 한다.
}
void ThreadDemo::Mutex()
{
thread t([&]()
{
while (true)
{
// Sleep 함수는 1 / 1000초 밀리 세컨드 단위(0.001초)
Sleep(1000);
// mutex에서 progress를 접근하게 된다.
// Update()에서도 progress를 접근하게 됨
// Update(), Render() 이런 함수들도 메인스레드로 취급됨
// 여기서 스레드를 하나더 하니까, 멀티 스레드가 됨
printf("Progress : %f\n", progress);
// 결국 Update() -> 메인 스레드가 progress를 접근하고(써주고)
// 여기 Mutex() 함수에서 이 스레드가 progress를 접근한다.
// 지금 상황에서 누가 먼저 가져다 쓰는냐는 중요하지 않음
// 사람들이 이거 정상적으로 잘실행되서(미세하게 차이남)
// 결국 MutexUpdate()에서의 progress를 출력하는 것과
// Mutex()에서 Progress 출력하는 값이 미세하게 차이가 남
// -> 미세한 차이가 나중에 황당한 일이 발생할 수 있음
}
});
// join()은 자기 스레드가 종료될때 까지, 대기를 시키지만
// detach()는 스레드의 종료에 관계 없이 대기 없이 다음으로 넘겨주고, 스레드가 완료되면 자동으로 join을 발생시키는 함수
t.detach();
}
void ThreadDemo::MutexUpdate()
{
progress += 0.01f;
// 0 ~ 1까지 비율로 되어있다.
// 그래서 1 / 1000초니까 1000으로 나눔
ImGui::ProgressBar(progress / 1000.0f);
}
void ThreadDemo::RaceCondition(int& counter)
{
for (int i = 0; i < 10000000; i++)
{
// 어떤 스레드가 counter에 접근했다면 자기 스레드를 묶는 것이다.(mutex를 통해)
m.lock();
{
// counter는 lock()하는 순간에 임계영역으로 바뀜(counter가 임계영역으로 묶임)
counter++;
}
// unlock() 안해주면 다른 애들이 못들어가는 교착상태(데드락)이 되버림
m.unlock();
}
// 결과 : 시간은 걸리나(연산이 느려짐) 총 40000000이 되는 것을 알 수 있음
}
void ThreadDemo::Execute()
{
int counter = 0;
// counter가 참조가 일어나서 각 스레드에 참조가 된다.
// 각 스레드가 10000씩 더해서 총 40000이 된다.
vector<thread> threads;
for (int i = 0; i < 4; i++)
{
// 인자가 있다면 placeholders 해줘야함
function<void(int&)> f = bind(&ThreadDemo::RaceCondition, this, placeholders::_1);
// 레퍼런스로 넘길때는 function의 ref() 함수로 넘겨야 한다.
// 안그러면 에러남
threads.push_back(thread(f, ref(counter)));
}
for (int i = 0; i < 4; i++)
threads[i].join();
printf("Counter : %d\n", counter);
// 각 10000할때는 총 40000으로 잘나옴
// 그런데 값을 올려보니(10000000을 해보니)
// 총 17418799이 나옴(총 40000000이 나와야 하는데)
// 이유는 순서대로 하나씩 접근해서 참조해서 증가해야하는데
// 카운터를 서로간의 뺏어가다 보니까, 누가 먼저 더할지도 모르겠고
// cpu 연산중에 더하고 다른애가 더하고 해야한는데
// 다른애가 더하는 중에 뺏어서 들어가서 더하는 동작이 완료가 안되었는데
// 다른 애가 또 뺏어가고...
// 완료 안된 상태로 화장실을 나가야하는...
// 서로 간의 계속 싸움(Race Condition(교착상태)
// 그것을 해결하기 위해 mutex로 lock()을 걸어줌
}
void ThreadDemo::ExecuteTimer()
{
// 2가지 케이스로 사용
timer.Start([]()
{
printf("Timer\n");
}, 2000, 2);
// 뒤에는 Start 변수 인자들
// 2000은 밀리세컨드로 2초
// 2초 마다 2번 실행시키겠다는 얘기
// 2초마다 나오도록
timer2.Start([]()
{
printf("Timer2\n");
}, 3000);
// 아무것도 입력안하면 뒤에 디폴트 파라미터로 0을 줬다.
// 0은 무한대로 실행해라(3초마다 계속 실행함)
}
void ThreadDemo::ExecutePerformance()
{
int arr[10000];
for (int i = 0; i < 10000; i++)
arr[i] = Math::Random(0, 100000);
Performance p;
p.Start();
{
// 1 : 정렬을 시작할 iterator(시작 주소), 2 : 정렬을 완료할 iterator(끝 주소)
// iterator는 사실 주소이기도 하다.
sort(arr, arr + 10000);
}
float last = p.End();
// Performance는 완벽한 초 단위가 아니라서, 상대적인 시간 수치비교용
printf("총 수행시간 : %f\n", last);
// 밀리 세컨드 단위로
// 총 수행시간 : 14.618200 나왔다면 14.618200 / 1000 초 걸린것이다.
}'DirectX11 3D > 기본 문법' 카테고리의 다른 글
| <DirectX11 3D> 59 - ComputeShader(CS)(1) - RawBuffer(ByteAdress) (0) | 2022.02.24 |
|---|---|
| <DirectX11 3D> 58 - ComputeShader(CS) 이론 (0) | 2022.02.24 |
| <DirectX11 3D> 53 - Instancing(Animation) (0) | 2022.02.22 |
| <DirectX11 3D> 52 - Instancing(Model) (0) | 2022.02.22 |
| <DirectX11 3D> 51 - Instancing(Mesh) (0) | 2022.02.22 |


