필요한 개념
DirectCompute 이론
DirectCompute : ComputeShader(컴퓨트 셰이더)를 동작시키는 다이렉트X의 라이브러리가 다이렉트 컴퓨트
렌더링 파이프라인이라는 것은 화면에 뭔가를 그리기 위한 과정
여기 Shader(VS, PS)는 렌더링 파이프라인으로 호출되는 거지 우리가 임의로 호출 불가
근데 렌더링 파이프라인과 별개로 동작시킬 수 있는 Shader가 하나 더 있다.(-> ComputeShader(CS))
ComputeShader(CS)는 계산용으로만 사용되므로 렌더링 파이프라인과 별도로 동작한다.
* ComputeShader(CS)가 나온 배경
엔비디아가 GPU라는 만들어낼때 GPU를 가속시키다 보니까
GPU를 프로그래밍할 수 없을까? GPU도 CPU 처럼 처리를 위한 UNIT이니깐(그래픽 전용)
그래서 나온게 Shader이다.
그래픽 카드를 임의로 프로그래머가 조작할 수 있도록 만들어 놓은 언어가 shader
나중에 보니 그래픽만 처리하기 에는 아깝고, shader는 사용가능한 자료형이 float형 하나이다.
float을 사용하는게 그래픽만이 아니고, 물리도 float을 사용할 수 있을 것같다.-> 그래서 엔비디아에서 CUDA라는 언어를 발표
이제 그래픽만을 위한 그래픽카드만이 아니라, float을 처리하는 학문이면 어떠한 학문이더라도 CUDA라는 언어 만듬
CUDA -> 물리만 사용되다가, 엔비디아 그래픽카드를 사용하면(옷이나, 머리같은게) 더 물리적용이 잘 된다는 게 CUDA 덕
처음에는 CUDA가 엔비디아에서만 사용가능했다. 주로 게임에 물리처리용으로 많이사용
세월이 지나가면서 왜 엔비디아만 사용하냐 AMD도 사용하고 싶어서 통합하는 움직임 생김
-> 어떤 그래픽카드에도 상관없이 그런 Shader를 쓸 수 있도록 하자 개념이 DirectX 진영에서는 DirectCompute 라이브러리를 만들고
ComputeShader라고 명명함
오픈지엘 진영에도 자기만의 ComputeShader인 Opencl이라는 것을 가지고 있다.
자료형은 float형 하나지만 다양한 프로그래밍이 가능, 여러가지 영역 가능 -> 딥러닝도 이제는 본격적 활성화, 비트코인도 데이터를 쪼개서 분산하는
대규모 스레드사용
물리도 대규모 스레드 처리이다.(건물 무너지는 것을 생각하면 건물의 한 구역, 돌덩이 하나하나를 스레드로 놓고 처리) -> 이런 개념이 ComputeShader이다.
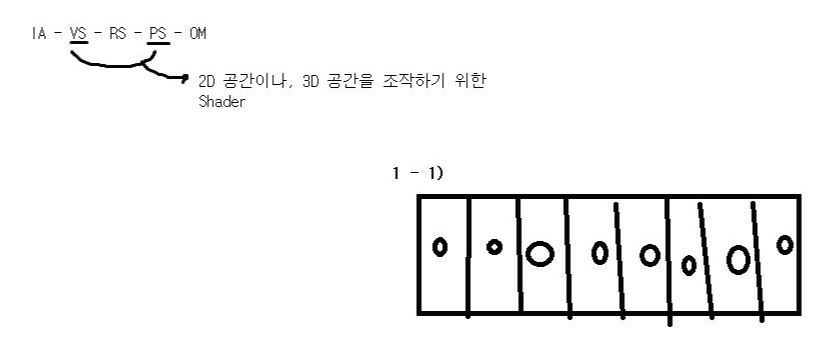
우리가 ComputeShader로 할려는 개념은
캐릭터의 애니메이션 연산을 CS에 맡김(렌더링은 그대로 두고, 애니메이션 코드를 동일하게 가져와서, 팔꿈치 bone, 손 bone의 위치를 구함)
-> 왜 하필 CS로 사용하나?
그게 유리하다. CS는 예를 들어 건물이 무너진다면 같은 돌댕이 여러개가 쏟아지는데 그 돌들 하나하나가 스레드
우리는 캐릭터 100, 200개 최대 500개(우리가 설정한 최대 인스턴싱 값) 해서, 하나하나를 스레드로 보고 500개를 거의 동시에 실행시켜서 각각 다른 애니메이션 하드에 있는
손의 bone을 가져올 것이다. 그런 대량으로 있는 데이터를 나눠서(쪼개서) 처리하는 다 똑같은 형태인데, 값만 다른것들 이런것들은 모두 CS로 다룰 수 있다.
-> 형태가 같고 값이 다른 것들은 분할 가능! 분할이 가능한 것은 스레드나 CS로 처리가능(사진 1 - 1 참고)
텍스쳐도 대량으로 쪼개지는 데이터 아닌가요?
-> 맞다. 그래서 텍스쳐도 픽셀 하나하나를 CS의 스레드 하나로 취급하고 연산할 수 있다.
이전에 VS에도 하나의 정점에 하나의 스레드가 붙는다고 말했고, PS에도 하나의 픽셀에 하나의 스레드가 붙는다고 했다.
결국에는 애초에 GPU자체가 스레드가 동작을 하고 있다.
예전에는 CPU 코어가 4 ~ 8개지만, 명령어 셋도 크고 자료형도 다양하게 처리가능, GPU 쓰레드개수가 4000개이다. 명령어 셋도 적고 처리할 수 있는 자료형은 float하나다.
CPU는 머리 좋은 천재 여러명있고, GPU는 노가다꾼 3000명이 있다.
결국에는 3000명을 어떻게 처리할꺼냐?
반복되는 작업을 쪼개 줄 수 있다면(예를 들어 픽셀이 10000개라면, for i ~ 10000개가 돈다면 GPU에는 10000개를 쪼개서 GPU로 스레드로 쪼개서 준다, 3000명을 활용하자)
복잡한 연산이라면 CPU를 활용하면 되지만, 비트 코인 채굴 같은거, 딥러닝은 그렇게 복잡한 알고리즘이 아니라서, Bone을 구해오는 것도 복잡하지 않다.
문제를 스레드로 쪼개서 GPU에게 맡겨서 처리하겠다.(우리가 처리하는 데이터가 float으로 바뀔 수 있다면, 쪼개서 한번에 처리하겠다가 ComputeShader이다.)
CPU는 복잡하고 고급적인 데이터, 여러자료형 데이터 처리 중점, GPU는 단순 쪼갤수 있는 반복적인 작업들을 쪼개서 float 자료형 하나로 뭔가를 처리하겠다. GPU 개념
ComputeShader : DX에서 DirectComputeShader Library를 통해서 사용
* 총 3가지 버퍼를 사용할 것이다.
- RawBuffer(ByteAdress 라고 부름) : 바이트 단위로 CS에서 다루게 되는 버퍼
- Texture2DBuffer : 2차원 배열을 CS에서 사용할 수 있도록 해주는 버퍼(픽셀 하나하나를 하나하나의 스레드로 나눠서 연산을 수행)
- StructuredBuffer : 구조체를 CS로 넘겨 구조체 단위로 사용(Raw 버퍼와 비슷하지만, 보통 ByteAdress 보다 StructuredBuffer를 더 많이씀)
Raw : Cpu에서 Gpu로 넘길때의 개념
알고리즘 중에 분할정복이 있는데 분할정복이 적용 가능하다면 Thread로 처리가 가능하다.
픽셀을 처리한다고보면 픽셀을 하나하나로 분할 할 수 있다, 그것다음 전부다 스레드로 맡겨서 처리하고, 텍스쳐로 합친다면 -> 분할정복이 된다.
스레드로 쪼개면 쪼갤수록 처리속도가 올라감
CPU 스레드를 처리한다는것은 굉장히 까다롭고 어려운 개념(단위가 워낙 커서)
GPU는 쉽다.(애초에 설계가 되게 많은 숫자를 가지도록 설계, 우리는 VS, PS 할때 이미 사용되던것)
'DirectX11 3D > 기본 문법' 카테고리의 다른 글
| <DirectX11 3D> 62 - ComputeShader(CS)(2) - TextureBuffer (0) | 2022.02.24 |
|---|---|
| <DirectX11 3D> 59 - ComputeShader(CS)(1) - RawBuffer(ByteAdress) (0) | 2022.02.24 |
| <DirectX11 3D> 56 - Thread(스레드) (0) | 2022.02.23 |
| <DirectX11 3D> 53 - Instancing(Animation) (0) | 2022.02.22 |
| <DirectX11 3D> 52 - Instancing(Model) (0) | 2022.02.22 |


